(Optional) Create a Sonatype nexus account following instructions in Maven Release in 5 Minutes. If you don’t use nexus, make sure to configure the workflow to download the war file from somewhere else.
Project Structure
As you see, the pipeline is a relatively complex one, with branching (7) and human intervention (9).
Steps
Go to where you checked out the code. Read the README.md files to see what you need to change. Then start the VMs by running
$ cd jenkins-vm
$ vagrant up
$ cd tomcat-vm
$ vagrant up
Once the VMs are up, open a browser and go to 192.168.2.4:8080. You should see a job workflow-demo-01. Click on it and click “configure”.
First change the “tomcat_username” and “tomcat_password” to the value you’ve configured for tomcat-vm.
Then modify the workflow script. The comments point out where the line corresponds to in the diagram.
node {
def mvnHome = tool 'Maven'
def devHost = '192.168.2.3'
def prodHost = '192.168.2.3'
dir('dev') {
stage 'Dev build'# 1
git url: 'https://github.com/ryan-ju/resteasy-demo-01.git'
// Print version
def v = version()
if (v) {
echo"Building version ${v}"
}
# 2
sh "${mvnHome}/bin/mvn clean install"
stage 'Dev deploy'# 3
deploy("resteasy-demo-01-server/target/resteasy-demo-01-*.war", devHost, "/dev")
}
dir('dev-test') {
stage 'Dev QA'# 4
git url: 'https://github.com/ryan-ju/resteasy-demo-01-test.git'# 5
sh "${mvnHome}/bin/mvn -Dhost=http://${devHost} -Dport=8080 -Dcontext=/dev/api clean install"
}
dir('dev') {
stage 'Upload artifact'
// Print version
def v = version()
if (v) {
echo"Uploading version ${v}"
}
# 6
sh "${mvnHome}/bin/mvn -Dmaven.test.skip=true -P nexus deploy"
}
# 7if (release.toString().toBoolean()) {
dir('dev') {
stage 'Release build'
sh "git checkout master"
sh "git pull origin master"
def rv = releaseVersion()
# 8
sh "${mvnHome}/bin/mvn -P nexus -Darguments=\"-DskipTests\" release:prepare release:perform"if (rv) {
// Ask for manual permission to continue# 9
input "Ready to update prod?"# 10
sh "curl -L -o resteasy-server.war https://oss.sonatype.org/service/local/repositories/releases/content/org/itechet/resteasy-demo-01-server/${rv}/resteasy-demo-01-server-${rv}.war"# 11
deploy("resteasy-server.war", prodHost, "/resteasy")
} else {
error "Failed to get release version from pom.xml"
}
}
}
}
// Get version from pom.xml
def version() {
def matcher = readFile('pom.xml') =~ '<version>(.+)</version>'
matcher ? matcher[0][1] : null
}
// Get release version from snapshot pom.xml
def releaseVersion() {
def matcher = readFile('pom.xml') =~ '<version>(.+)-SNAPSHOT</version>'
matcher ? matcher[0][1] : null
}
// Deploy file to tomcat
def deploy(file, host, context) {
sh "curl -T ${file} -u \"${tomcat_username}:${tomcat_password}\" http://${host}:8080/manager/text/deploy?path=${context}&update=true"
}
Explanations
Jenkins workflow script is a DSL. The most important ones are:
node keyword specifies a chunk of task that should be scheduled on a node. It comes with a workspace (you can’t specify it).
dir keyword allows you to create a work dir under the node’s workspace.
stage is used to control the concurrency of a section of code. For example, you only want one build to deploy to Tomcat at a time, so should set this value to 1.
input asks for user intervention.
parallel allows multiple actions to run in parallel.
sh executes commands.
Output
At the moment, this is all the visualization you get:
Pretty ugly right? You’ll have to wait till the Cloudbees’ visualization plugin is open sourced, which will be early 2016.
Conclusion
Jenkins workflow is pretty painful to set up (totally my option, you’re welcome to disagree). The official tutorial doesn’t tell enough, neither does the Cloudbees doc. I personally found stackoverflow more informative.
To make matters worse, there are certain important features that are only available in Cloudbees enterprise, like workflow visualization and checkpoint (also, I still haven’t figured out how to wipe out the workspace, other than logging in and rm the whole dir. Indeed, such important functionality isn’t implemented yet!).
IMO, Jenkins workflow does work, but if you to make your life easier and have some fortune to spare, probably Cloudbees is a better choice to run Jenkins.
Next time I’ll have a look at GoCD, the new CD tool that’s getting lots of attention and is supposed to be much better.
Please leave a comment if you like this post or want anything improved.
This is a very short summary of how Maven release works and how to configure it.
Prerequisite
You should know what Maven lifecycle, phase, goal and plugin is.
Release Life Cycle
maven-release-plugin does not bind to any phase. This means your project won’t be released when you run a phase. Instead, you have to explicitly run the goals of the plugin.
The two most important goals are:
release:prepare - create a release tag in the scm, create a release.properties file and backup files, and update the project version. Full description
release:perform - checkout the release tag and upload to a repository. Full description
Note release:prepare is idempotent, so multiple runs doesn’t change anything. To re-prepare, add command line option -Dresume=false, which will delete release.properties and backup files.
Alternatively, you can run mvn release:clean release:prepare.
Perform Release
What is performed during release can be configured with the goals configuration.
E.g., if you want to upload artifacts to Sonatype, you can add nexus-staging-maven-plugin, which will perform the upload in deploy phase and release (to Maven central) with nexus-staging:release, like this:
<plugin><groupId>org.sonatype.plugins</groupId><artifactId>nexus-staging-maven-plugin</artifactId><version>1.6.6</version><!-- This plugin is an extension to the deploy phase, adding a new deployment type --><extensions>true</extensions><configuration><!-- The server ID configured in settings.xml --><serverId>ossrh-server</serverId><nexusUrl>https://oss.sonatype.org/</nexusUrl><!-- Not important for snapshots --><autoReleaseAfterClose>false</autoReleaseAfterClose></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-release-plugin</artifactId><version>2.5.3</version><configuration><autoVersionSubmodules>true</autoVersionSubmodules><useReleaseProfile>false</useReleaseProfile><releaseProfiles>release</releaseProfiles><!-- This will release the artifacts after staging them --><goals>deploy nexus-staging:release</goals></configuration></plugin>
Configure SCM Provider
Maven already supports many scm systems. The only thing you need to do is to make sure the <scm> tag is configured correctly. The release plugin uses it to pull and push changes.
release:rollback allows you to rollback a release, but only if you haven’t run release:clean. More details
Generate Release POM
release:prepare-with-pom generates a release-pom.xml, which contains all resolved dependencies, so all dependencies (including transitive) are explicitly defined.
Dry Run
All goals can be dry run with -DdryRun=true. This will still generate the properties and backup files, but won’t change any code or commit anything.
Chances are you’re already using the Maven Central Repo, which is the default repo when you installed Maven. Today I’ll show you how to publish your artifacts to it.
Backgrounds
The Central Repository (http://search.maven.org/) is an index containing all publicly available Maven artifacts. Maven by default downloads all dependencies from the Central Repo . It does not host the files. Instead, you need to use one of the repo hosting services, and then publish your files to the Central Repo. I’ll demo the following services:
Sonatype OSSRH
JFrog Bintray
I recommend reading Comparing the Two to choose your preference first.
More Backgrounds on Sonatype
Sonatype’s repo system is a bit complex. I’ll try my best to make it simple (after reading the nexus book).
Sonatype Professional is a repo system. OSSRH is a free publicly available Sonatype Profressional.
(For Sonatype) Register a group ID. To do this, create a Jira ticket like this.
(For Bintray) Register a Bintray account.
Make sure your’re familiar with Maven release plugin. You can read Maven release in 5min.
Warning
It usually takes a couple of days for Sonatype group ID to get approved.
Also, you may need to prove that you own a domain if your group ID is a domain name.
Please read the registration policy.
Then configure the plugins. See comments for explanation.
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-source-plugin</artifactId><version>2.4</version><executions><execution><id>attach-sources</id><goals><goal>jar-no-fork</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-javadoc-plugin</artifactId><version>2.10.3</version><executions><execution><id>attach-javadocs</id><goals><goal>jar</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-gpg-plugin</artifactId><version>1.5</version><!-- Automatically gets passphrase from property gpg.passphrase --><executions><execution><id>sign-artifacts</id><phase>verify</phase><goals><goal>sign</goal></goals></execution></executions></plugin><plugin><groupId>org.sonatype.plugins</groupId><artifactId>nexus-staging-maven-plugin</artifactId><version>1.6.6</version><!-- This plugin is an extension to the deploy phase, adding a new deployment type --><extensions>true</extensions><configuration><!-- The server ID configured in settings.xml --><serverId>ossrh-server</serverId><nexusUrl>https://oss.sonatype.org/</nexusUrl><!-- Not important for snapshots --><autoReleaseAfterClose>false</autoReleaseAfterClose></configuration></plugin></plugins></build>
nexus-staging-maven-plugin
The available goals include deploy, release and drop. For full list, see here.
(Optional) Execute mvn nexus-staging:release to upload artifacts to
First, you need to run
mvnrelease:prepare
Then run
mvnrelease:perform
which will upload the artifacts to a staging repo. This is because the perform goal by default runs a deploy phase, and the nexus plugin’s deploy goal is bound to deploy phase. To configure what phases are run by perform, set the <goals> configuration.
You can now release the artifacts with (reference)
mvnnexus-staging:release
Alternatively, you can do release with Maven release plugin(reference)
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-release-plugin</artifactId><version>2.5.3</version><configuration><autoVersionSubmodules>true</autoVersionSubmodules><useReleaseProfile>false</useReleaseProfile><releaseProfiles>release</releaseProfiles><!-- This will release the artifacts after staging them --><goals>deploy nexus-staging:release</goals></configuration></plugin>
where the api key can be found in you Bintray profile
Then create a package in your Bintray’s Maven repo. This is a Bintray specific tag for organizing artifacts. In my case I created “resteasy-demo-01” package.
Now edit your pom.xml to include
The scm tag so the release plugin can update the versions
The remote repo
The necessary plugins
<scm><connection>scm:git:git@github.com:ryan-ju/resteasy-demo-01.git</connection><developerConnection>scm:git:git@github.com:ryan-ju/resteasy-demo-01.git</developerConnection><url>git@github.com:ryan-ju/resteasy-demo-01.git</url><tag>HEAD</tag></scm><distributionManagement><repository><id>bintray-repo-maven</id><url>https://api.bintray.com/maven/ryan-ju/maven/resteasy-demo-01/</url></repository></distributionManagement><!-- Dependencies go here --><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-source-plugin</artifactId><executions><execution><id>attach-sources</id><goals><goal>jar-no-fork</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-javadoc-plugin</artifactId><executions><execution><id>attach-javadocs</id><goals><goal>jar</goal></goals></execution></executions></plugin><plugin><artifactId>maven-release-plugin</artifactId><version>2.5.3</version><configuration><autoVersionSubmodules>true</autoVersionSubmodules></configuration></plugin></plugins></build>
Then you can release your artifacts to Bintray
# This creates a tag for the release version in GitHub, and increment to the next SNAPSHOT version (e.g., 1.0.1-SNAPSHOT to1.0.2-SNAPSHOT).
# This also generates a release.properties filein your work dir
# As long as release.properties exists, this command is idempotent.
mvn release:prepare
# This command releases artifacts to remote repo. The actual files are from the release version, not the snapshot (obviously).
mvn release:perform
And you should see the artifacts under the package you created.
Up till now, the file aren’t publicly available. To publish them (to your repo, not Maven Central), click the button
Now you can use the repo in other projects by including the following in pom.xml
Warning
You should also configure the gpg key used to sign your artifacts. This can be done by clicking “Edit” in your Bintray profile and add a public key in the format
You need to click “Add to JCenter” button in your repo and give a group ID you want to publish under.
and then I guess you just need to wait for it to be approved.
Once that’s done, you should be able to find it in the Central Repo.
Comparing the Two
Both of the hosting services offer staging and publishing ability.
Bintray is easier to set up and can be used straight away (without requesting for a group ID), but can only host release versions of files (no SNAPSHOTs). The web UI is more intuitive and easier to use.
Sonatype is more complicated, but you can stage both snapshot and release versions of your artifacts. The web UI isn’t as pretty as Bintray, but still usable.
Weave and Flannel are currently the two main solutions to overlay networks for containers. They both try to solve the problem: how do you assign an IP to each container to connect them, when each container host can only have one IP.
They both employ the IP encapsulation approach: carrying layer2 (link layer) frames inside UDP datagrams.
The difference lies in the implementation details, which you can find in this post. The post also has a network performance test between the two, but doesn’t look at Weave fast datapath.
So in this post, I will compare three different setups: Weave with/without fast datapath, and Flannel.
Setup Weave
I launched 2 EC2 instances (t2.medium on hvm) in the same AZ.
To set up Weave, Weave doc is all we need, and is easy to follow.
Setup Flannel
Setting up Flannel is more involved. The steps are here: Set up an etcd cluster.
# On both hosts# Download and untar etcd
$ curl -L https://github.com/coreos/etcd/releases/download/v2.2.2/etcd-v2.2.2-linux-amd64.tar.gz -o etcd-v2.2.2-linux-amd64.tar.gz
$ tar xzvf etcd-v2.2.2-linux-amd64.tar.gz
# On HOST0, replacing $HOST0 and $HOST1 with the EC2 private IP
$ export ETCD_INITIAL_CLUSTER="infra0=http://$HOST0:2380,infra1=http://$HOST1:2380"
$ export ETCD_INITIAL_CLUSTER_STATE=new
# Start etcd server in the background
$ nohup ./etcd-v2.2.2-linux-amd64/etcd -name infra0 -initial-advertise-peer-urls http://$HOST0:2380 -listen-peer-urls http://$HOST0:2380 -listen-client-urls http://$HOST0:2379,http://127.0.0.1:2379 -advertise-client-urls http://$HOST0:2379 -initial-cluster-token etcd-cluster-1 &
# On HOST1, replacing $HOST0 and $HOST1 with the EC2 private IP
$ export ETCD_INITIAL_CLUSTER="infra0=http://$HOST0:2380,infra1=http://$HOST1:2380"
$ export ETCD_INITIAL_CLUSTER_STATE=new
# Start etcd server in the background
$ nohup ./etcd-v2.2.2-linux-amd64/etcd -name infra1 -initial-advertise-peer-urls http://$HOST1:2380 -listen-peer-urls http://$HOST1:2380 -listen-client-urls http://$HOST1:2379,http://127.0.0.1:2379 -advertise-client-urls http://$HOST1:2379 -initial-cluster-token etcd-cluster-1 &
Install Flannel
# On both hosts$ curl -Lhttps://github.com/coreos/flannel/releases/download/v0.5.5/flannel-0.5.5-linux-amd64.tar.gz -o flannel.tar.gz
$ tar zxf flannel.tar.gz
# On one host$ ./etcd-v2.2.2-linux-amd64/etcdctl set /coreos.com/network/config '{ "Network": "10.1.0.0/16", "Backend": { "Type": "vxlan"} }'
Host Connection Test
Install iperf on each host.
# ===TCP===# On HOST0
$ iperf -f M -i 1 -m -s# On HOST1
$ iperf -f M -t 60 -i 1 -c $HOST0# Output
[ 3] 0.0-60.0 sec 6887 MBytes 115 MBytes/sec
[ 4] MSS size 8949 bytes (MTU 8989 bytes, unknown interface)
# ===UDP===# On HOST0
$ iperf -f M -i 1 -m -su
# On HOST1
$ iperf -f M -i 1 -t 60 -m -c $SERVER -b 1000M
# Output
[ 4] 0.0-10.1 sec 562 MBytes 55.7 MBytes/sec 0.088 ms 450/401197 (0.11%)
Weave without Fast Datapath Test
First, we need to start Weave without fast datapath, using env variable WEAVE_NO_FASTDP.
Note the performance is over 20% less than host connection. Let’s enable fast datapath.
Weave with Fast Datapath Test
Weave requires some work to stop.
# On both hosts. For HOST1, change test-serverto test-client.
$ docker rm -f test-server
# Necessary to put DOCKER_HOST back to its original value
$ eval"$(weave env --restore)"
$ weave stop
$ weave reset
Now restart Weave as above, but without WEAVE_NO_FASTDP=true.
Er … fast datapath seems to make performance worse ???!!!
Set Proper MTU
It turns out Weave by default has MTU set to 1410, despite AWS VPC can handle 9001. We need to tell Weave to use a higher value, as it can’t detect it automatically (at least I didn’t find out how).
$ WEAVE_MTU=8950 weave launch
And the test result looks much better
# Without fast datapath# ===TCP===
[ 3] 0.0-60.2sec5050 MBytes 83.9 MBytes/sec# ===UDP===
[ 3] 0.0-60.0sec3895 MBytes 64.9 MBytes/sec0.291 ms 1349488/4127983 (33%)
# With fast datapath# ===TCP===
[ 4] 0.0-60.0sec6897 MBytes 115 MBytes/sec# ===UDP===
[ 3] 0.0-60.2sec3245 MBytes 53.9 MBytes/sec0.518 ms 1808496/4123433 (44%)
Ok the results look more reasonable, expecially that TCP with fast datapath is the same as host speed now (of course there is some error variance, but shouldn’t be that much).
Flannel Test
Flannel seems to be able to automatically detect the network MTU, so we don’t need to care about it.
To start Flannel,
# On both hosts$ nohup ./flannel-0.5.5/flanneld &
$ source /run/flannel/subnet.env
$ nohup docker daemon --bip=${FLANNEL_SUBNET} --mtu=${FLANNEL_MTU} &
Now Docker daemon is configured to use Flannel’s overlay network.
As we see, the performance is nearly the same as host speed.
Conclusions
Setup
TCP
UDP
Host
115MB/s
55.7MB/s
Weave without Fast Datapath, default MTU
86.1MB/s
43.9MB/s
Weave with Fast Datapath, default MTU
42.4MB/s
23.9MB/s
Weave without Fast Datapath, MTU=8950
83.9MB/s
64.9MB/s
Weave with Fast Datapath, MTU=8950
115MB/s
53.9MB/s
Flannel with backend=vxlan
114MB/s
51.2MB/s
Weave with Fast Datapath (and correct MTU) seems to have the same performance as Flannel.
UDP performance seems to be varying quite a lot during the tests, so the values above may not be representative. Indeed, when I used -l 8950 in iperf, the performance dropped to ~30MB/s. I’m not sure if this is due to some kind of throttling on AWS, but this happens with all of the setups.
Weave fast datapath currently doesn’t support encryption, so it’ll be down to the application to do that.
When current build tool lacks some features:
Java dev: write a Maven plugin
Scala dev: write an SBT script
Ruby dev: write a new Rake task
JS dev: write a new build tool
You need three things to activate Windows 7 OEM (or rather, bypass the activation)
An OEM certificate
A SLIC signature corresponding to the OEM certificate in BIOS
A product key
There are many SLIC signatures and OEM certificates online, decoded from various PC manufacturers. You need to inject the SLIC signature into your BIOS (dangerous!!!), and import the OEM certificate into Windows after installation.
Product key only determines the version of Windows (flagship, ultimate, home, etc), and has no connection to the other two.
With VirtualBox
VirtualBox provides a convenient way to edit SLIC table. After creating a new VM, go to the VM’s folder and edit the .vbox file.
Make sure you close VirtualBox before editing the .vbox file, otherwise your edits will be removed.
# Add the following line before </ExtraData> tab
<ExtraDataItem name="VBoxInternal/Devices/acpi/0/Config/SLICTable" value="/path/to/SLIC.BIN"/>
Then in the VM, copy over the OEM certificate and run
DevOps is the new buzzword in software industry these days, but what exactly does it mean? Why is it important? What are the concepts and tools to make it happen? So today I will demonstrate these by a very simple project: a Cassandra cluster.
Here is a simple illustration of what the end result is like:
The tools we will be using are (some familiarity of the tools may be helpful, but not required for this demo. I will cover all the necessary bits.):
Cassandra - a NoSql database
OpsCenter - a monitoring server for Cassandra
ChefDK (chef-solo, berkshelf, knife) - a server provisioning tool
Vagrant - a vm management tool
Packer - a vm box builder
AWS - Amazon web services
And here is an illustration of the deployment process:
Resources
https://github.com/ryan-ju/aws-cassandra
The Git repo contains all the required code and scripts. We’ll use that as base directory throughout this post. Check it out!.
Before we start
Make sure you have an AWS account and have set up an access key with admin privilege (or a more restricted one if you know what to do).
You should also have AWS CLI installed. The most convenient method is with pip.
Steps
Outline
Build Vagrant base image for local testing
Build AMI with Packer
Create cookbook
Test the cookbook locally with Vagrant
Upload the cookbook to S3
Use Cloudformation to create a Cassandra stack and an OpsCenter stack (in the same subnet in a VPC)
Tip:
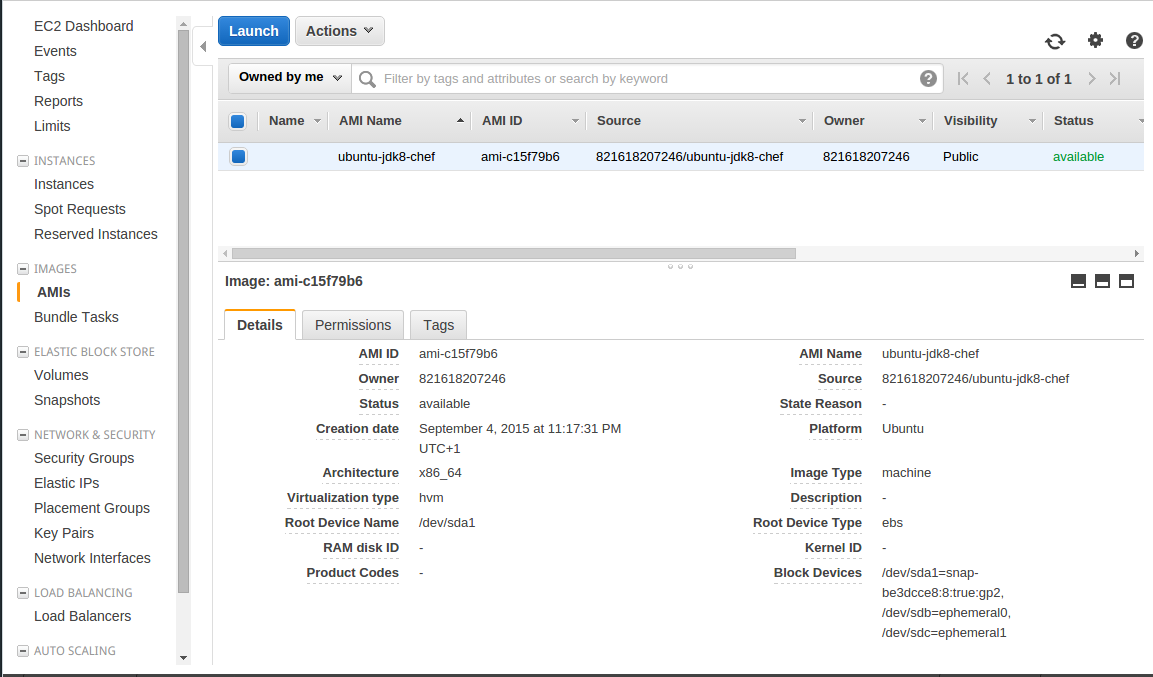
Steps 1 and 2 can be skipped if you only want to do the deployment part. I have created a public AMI for you ami-c15f79b6.
A brief intro of Vagrant
Vagrant is a VM manager. It’s an abstraction layer between user and VM implementations like VMWare, Virtualbox and EC2 etc, providing a common interface to create, provision and destroy VMs.
Vagrant has a similar style as Docker. You create a Vagrantfile and use it to tell Vagrant how to create a VM.
You run vagrant up to start a VM, vagrant ssh to log into it, and vagrant destroy to remove the VM.
Note:
If you use the installer to install Vagrant, it will come with its own Ruby, which won’t interfere with your current Ruby environment if you use RVM (joy~~).
Next, download a copy of JDK 8 and store that as base-image/vagrant/tmp/jdk<version>tar.gz. I didn’t check that into GitHub due to its huge size.
Next, cd to base-image/vagrant and run
vagrant up
Read the Vagrantfile and you’ll see that it uses the shell provisioner to
install JDK8 (using the tarball)
install Chef
install sysstat
Once the VM finishes booting, you can vagrant ssh to inspect it. If you’re happy, run vagrant package. This will create a package.box file in pwd (your working dir), which is a box you that you can launch VMs with.
Next, add the box to your Vagrant box list by vagrant box add stackoverflower/ubuntu-jdk8-chef package.box. This will add package.box by name stackoverflower/ubuntu-jdk8-chef. You can use a different name, but I’ll stick with this.
If you want to test if the box works ok, you can create a new project, run vagrant init to create a Vagrantfile, change the line to config.vm.box = "stackoverflower/ubuntu-jdk8-chef", and vagrant up.
Build AMI with Packer
A brief intro of Packer
Packer is a box builder. Like Vagrant, it abstracts out several VM implementations. It also has a single config file style. You create a packer.json file, specifying the implementation (called builder) and the provisioning, then run packer build packer.json and you’ll get your box built.
Why Packer for AWS?
If you ever used boxgrinder, you should know the pain of uploading an AMI to AWS (it takes AGES …). With Packer, it starts up an EC2 instance, provisions it, and builds an AMI from it. This is VERY quick.
Installing Packer
It’s distributed as a zip file, and you need some manual work to install it. I’ve created a bash script for Ubuntu systems. Please read it first (it’s not difficult).
cd to base-image/packer and read packer.json. Note the following:
"region": "eu-west-1" — the box will be in eu-west-1.
"source_ami": "ami-47a23a30" — the base AMI to use is a Ubuntu one in eu-west-1. If you change to another region, make sure you change this.
"ssh_username": "ubuntu" — the use that Packer will log into your EC2 instance as. For Ubuntu images, it’s “ubuntu”; for AWS linux, it’s “ec2-user”.
Also export the env vars AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. Packer needs them to authorize to use AWS CLI.
Now you’re ready to build your AMI. Run packer build packer.json and observe the output.
You should see the following in your AWS console (of course your AMI ID will be different):
Create Cookbook with ChefDK
A brief intro of Chef
Chef is a set of tools to automatically provision a VM. Provisioning is the process of creating and configuring resources.
The smallest unit of provisioning is a resource, like installing a package, creating a user or creating a file from a template. Also provider, as in Vagrant and Packer, provides concrete implementation for a resource.
A recipe contains a list of resources, together with some programming logic so you can configure the parameters(attributes) dynamically. Recipe can reference other recipes, forming a nested structure.
An attribute file contains the parameter values that the recipes need.
All of the above are packaged into a cookbook, the distribution unit of Chef.
But you should notice there is no “entrypoint” to the cookbook (which recipe to run?). This is provided by a runlist.
Chef can run in two modes: server-client and solo.
chef-solo
The tool we’ll be using. You run it on the VM you want to provision with the required cookbooks and a runlist, and it’ll take care of the rest.
Knife
A cookbook manipulation tool. Mainly for creating and uploading cookbooks to Chef server.
Berkshelf
Because recipes can reference recipes from other cookbooks, cookbooks can have dependencies on each other. Berkshelf is a dependency resolver for cookbooks. It requires a Berksfile in your cookbook dir, specifying what cookbooks it depends on and where to find them. It can also package all the cookbooks into a tarball, ready for chef-solo to run. This is what we’ll be doing.
cookbooks/cassandra-example is a cookbook I already created. You can inspect its content. The directory is generated with knife cookbook create cassandra-example.
The content means all dependent cookbooks are downloaded from “https://supermarket.chef.io“, but “cassandra-dse” is from a Git repo, and the dependencies in metadata.rb are included.
cookbooks/cassandra-example/recipes contains two recipes, and their names tell your what they provision.
Test the Cookbook Locally with Vagrant
You need to install the vagrant berkshelf plugin. This plugin intercepts any reference to the cookbook under test and redirect it to the working dir, so you don’t need to do berks install every time you make a change.
Then, read cookbooks/cassandra-example/Vagrantfile. Notice how it’s different from the Vagrantfile for the base image creation. It allows you to create multiple VMs, provision each one differently, and bridge them into the same network so they can communicate.
You can configure the number of seed/non-seed nodes with NODE_COUNT and SEED_NODE_COUNT.
Run
vagrant up
and after all VMs have started, type 192.168.2.254:8888 into your browser. You should see the following:
click on “Manage existing cluster” and type “192.168.2.100”, then click “OK”. You should see a console like this:
This means both Cassandra and OpsCenter are running correctly.
Build tarball with Berkshelf
Next, let’s build a tarball containing all the cookbooks required.
Run
berks install
This will install the current cookbook to your ~/.berkshelf/dir, as well as downloading all the dependencies. Once it’s done, run
where you should’ve created a bucket called bucket_name.
A brief intro of S3
S3 is simple storage service. You an upload and download files indexed by a unique URL (s3://…). Files are automatically replicated to prevent data loss.
There is a small charge to storage capacity used.
You should see your cookbook in your S3 console:
Use Cloudformation to Launch Stacks
Setup AWS account
Firstly, you need to create a VPC, a subnet and a security group in AWS eu-west-1.
A brief intro of VPC
AWS VPC allows you to create a private datacenter with custom access rules. Inside a VPC you can create multiple subnets and set routing rules to link them together. Each VPC can have multiple internet gateways to allow internet access from instances. Some basic IP networking is required to understand all of these, but AWS doc should be sufficient.
Here are the inbound rules of my security group:
Type
Protocol
Port Range
Source
ALL TCP
TCP (6)
ALL
sg-c815faac
ALL TCP
TCP (6)
8888
[Your own IP address]
SSH (22)
TCP (6)
22
0.0.0.0/0
Also you need to create a key pair for ssh.
One final step is to create IAM policy and role.
A brief intro of IAM
IAM (identity and access management) is a role based access control (RBAC) system. The idea is an admin should create roles, assign access policies to them and specify who can assume the role (called “principle”). For example, a role can be “tester”, a policy can be “read S3” and a principal can be “EC2”.
Go to IAM console -> Policies, click “Create Policy”, and select “Create Your Own Policy”. Policy Name = “s3-readonly”, Policy Document =
Go to the IAM console -> roles, and click “Create New Role”. Give it a name “ec2-tester”, click “Next”. Select “Amazon EC2”, and from the list select “s3-readonly”, click “Next”, and “Create Role”.
Launch Cloudformation Stacks
Now you’ve got AWS ready to launch Cloudformation.
A brief intro of Cloudformation
Cloudformation is a service to group and launch AWS resources as a stack.
Resources include EC2 instances, load balancers, auto scaling groups, IAM roles and policies etc.
Cloudformation uses a JSON template to launch a stack, which defines all the resources needed. Cloudformation is able to figure out the resource dependencies and launch them in the right order.
The template can also include parameters and outputs.
First, let’s launch a OpsCenter stack.
Inspect cloudformation/opscenterd-cloudformation.json. You should see that the file contains those sections: “Parameters”, “Mapping”, “Resources” and “Outputs”. In “Resources”, you should see that it creates one EC2 instance with some user data (a bash script).
Go to the Cloudformation console and click “Create New Stack”. Give the stack a name like “OpscenterExample01”, and select “Upload a template to Amazon S3”. Upload opscenterd-cloudformation.json, click next. You should see this:
CookbookS3: the “s3://[bucket_name]/[some]/[prefix]/[cookbook_name]” link to your cookbook tarball (Not the Link property you see in the console).
Ec2InstanceRole: the name of the IAM role you created
Ec2OpscenterdIp: an IP from the subnet you created.
KeyName: the name of the key pair you created
SecurityGroupId: the name of the security group you created
SubnetId
VpcId
Click “Next”, you don’t need any tags, so “Next” again, and tick the last box (Cloudformation needs confirmation that you want to create IAM resources) and click “Create”. You should see this:
Next, launch a Cassandra cluster. Follow the steps again, but this time upload “cassandra-cloudformation.json” and call the stack “CassandraExample01”. If you read the file, you should see it’ll create 3 seed nodes. Fill in the parameters, making sure you give the nodes different IP addresses. Click “Create”.
You should see both stacks are created, like this:
and all 4 instances are up:
Find the public DNS of your OpsCenter instance, and visit [You DNS:8888] in your browser, add the cluster IPs, and you should see:
Note: Don’t forget to terminate the stacks, otherwise you could be billed.
Conclusion
Now you should have the basic idea of how those tools work and how they form a full DevOps development cycle. The most important thing is to note that infrastructure is now managed as code, with versioning and tests to allow an agile style of development.
This demo isn’t perfect, and as an exercise, you should find out how to:
set up a CI server like Jenkins to automatically build and test cookbooks, and upload to S3/Chef server,
use Chef server to host the cookbooks instead of S3,
add an auto scaling group to the Cassandra stack so new nodes can be started when load goes up (but also consider the cool down policy),
back up and upgrade the cluster (maybe using ELB and route53?),
load test the cluster (see load-tests/ for an example)